2020年12月21日,《自然》撤稿了一篇一作为女性科学家的论文——The association between early career informal mentorship in academic collaborations and junior author performance,原因是违反科学实验协议以及错误地解读数据。该论文声称学界逐渐增长的女性导师会破坏女性科学家职业生涯初期的影响力。论文一经发布便引来口诛笔伐,替代计量引用迅速飙升。抛开文章结论,我们不禁要问:是什么阻碍了研究者从数据中得到真相?以及何种情况下,数据才能为假设提供证据?
时间来到1973年,加州大学副院长Hammel发现,申请伯克利研究生的男生中,有44%被录取了,而女生录取率只有35%。然而,当Hammel对每个院系进一步分析时,却发现所有院系的录取都是女生更高。为了明辨事实,避免遭受性别歧视的控诉,Hammel找来了Bickel分析数据,后者在1984年拿到麦克阿瑟天才奖,但彼时不过是一名初出茅庐的统计研究者。Bickel一眼就认出了数据中的辛普森悖论——在总体和亚组层面,数据呈现出截然相反的结论。
1975年,Bickel和Hammel等人在《科学》发表论文“sex bias in graduate admissions: data from Berkeley”,用因果层面的解释给出了辛普森悖论的解法:在总体层面,女性申请者被拒绝的比率更高,是因为她们更倾向于申请更难录取的人文与社科学科。这一解法有其合理性,因为辛普森悖论中正确的结论取决于特定的研究问题和研究假设。在伯克利招生悖论中,性别以学院为中介,作用于录取结果(当时路径分析体系还未被统计界认可)。因此性别歧视的合理定义应为性别对录取结果的直接,而非总效应。我们知道,计算直接效应,需要控制中介,意味着对性别分层,在亚组内考虑结论。因此伯克利是清白的。
但是故事到这里远未结束。当时大名鼎鼎的统计学家,如今广泛应用的非参数ANOVA的提出者,Kruskal,给Bickel等人发了一封质疑信。在通信中,Kruskal用假象数据限制了Bickel的结论:如果一个大学有两个存在性别歧视的院系,他们都接受所有本州男性和外州女性的申请,但拒绝所有外州男性和本州女性,仍然可以得到与Bickel手头一样的数据。此时,真实存在的性别歧视不再为中介模型所求出,何解?套用因果推断的术语,变量“院系”和“录取结果”中再次打开了一条后门路径,经由院系到居住州,再到录取结果,而居住州是二者的共同因。当数据集中不包含“居住州”时,控制院系而不控制居住州,得到的性别效应依然不是直接效应,而是直接效应和后门路径的效应。
因为时代背景下,缺乏特定的数学工具,Bickel在回复中无力解释质疑。Kruskal的评论在今天看来依然一针见血,对心理学以及其他社科研究依然由重要意义:在协方差分析中,一个研究者应该控制哪些变量;在路径分析中,必须放入哪些变量?这个问题的答案,对结论的正确性有着决定性的意见。
实际上,每一个受过良好统计学训练的心理学研究生,都已经在课上学到了这些问题的回答:基于理论得出图结构假设,再用数据支持;同时,必须在路径分析中放入混淆变量以免极大程度影响路径系数等。问题在于,人们往往忽视了一点,即结论的可靠性,首要取决于先验的因果理论,其次才是数据——数据很蠢,不会自己告诉我们结论。而现实中,人们倾向于把理论研究的问题,归咎于统计问题。
1920年,赖特在PNAS上发表了一篇进化生物学上里程碑式的论文,论文中,他第一次采用了一种被称为路径图的结构,用于探究遗传因子对小鼠毛色变异的影响强度。其方法的依据是,通过理论勾勒出现实世界的因果关系,再求解变量之间相关性,从而得到因果性的结论。一年后,赖特系统地总结了他的方法,发表了一篇名为correlation and causation的论文。要知道,当时的统计学界,将因果视为伊甸园的苹果,唯恐避之不及。
纵观历史,科学的发展中充斥着霸权主义以及以温文尔雅为表象的野蛮行径。皮尔逊的徒孙Pearl立即对赖特的方法论回应,并在论文中指出:the basis of the method of path coefficients is faulty. 与此同时,当时学界的领袖Fisher也将赖特视为自己的敌人,崇尚简约的统计学——统计学是一种收集数据并按照固定程序分析的科学。时间悄然而逝,63年之后的1983年,93岁高龄的赖特再次被学术界推上风口浪尖,不得不再次提笔,在遗传学期刊上回应数学家们对路径分析的批评——在这之间,他的理论本应是发展壮大。
赖特的理论在今天看来为什么是合理的?因为路径分析要求研究者不能服从一种固定的程式,而是对特定的研究以图形的方式提出特定的因果关系——概念,再辅以真实世界的数据进行验证——经验,从而从不同的信息源对客观真理进行验证。而这种思想并未被大众所理解,这使得路径分析在20实际后半叶走向了分水岭,一方面是心理学家和社会学家们结合验证性因素分析将其发展为结构方程模型(SEM)。伴随着LISREL的诞生,数据分析由不同信息源的交叉验证沦为软件使用,人们不再过问数据背后的真相;一方面,经济学家们发展了联立方程模型,彻底舍弃了路径图,不再考虑先验的理论意义。
时至今日,因果已经不再是统计界的禁忌,因果已经完成了从哲学含义到数学定义的转变,并有了专门的研究方向。显赫的成果,有贝叶斯网之父Pearl的因果识别研究,有卡内基梅龙团队的因果搜寻,也有Rubin的潜在结果模型。在因果搜寻算法层面,总体呈现出三个方向:一种是90年代兴起,由CMU团队发展的条件独立算法,经典的是PC,以及有潜在共同因时的FCI算法;一种是基于数据全局结构发掘因果关系的GES算法;最后一类是基于特定残差假定的函数式因果模型,典型的方法有LiNGAM,并搭载了基于ICA,或者是回归的独立性判定方法。
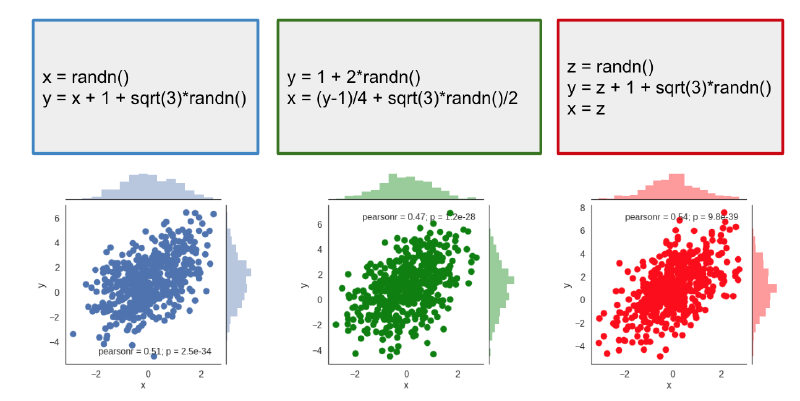
我们不禁要问,既然因果已经完成数学化,那么为什么学界依然面临因果关系的困境?或者说,如果把一个形而上学问题数学化并用公式表述,且发现数据符合该数学形式,为什么依然说认识论无法回答本体论问题? 结论是,因为数据符不符合数学表达是根据假设检验决定的,中间的决策是基于统计学不是数学,而统计是对客观真理的推测,总有出错可能,所以不能给出形而上学问题的回答。抛开少数因果方向不可识别的几种情况,抛开时序变化因果关系,我们知道的是,不同的算法会有其固有缺陷。比如PC算法由于其按数据集顺序抓取变量计算条件独立,极端情况下受到数据集变量顺序影响;此外,PC还受潜在共同因影响、在小样本时不满足因果充要条件。另外,在统计决策的层面,我们会面临一二三类错误。至少,我们还会面临测量变量有噪声的情况,测量变量呈现出难以处理的偏态分布或者因为抽样不当导致的混合高斯分布。更根本的问题是,我们无法先验地判断数据更符合哪种模型的假设,从而无法解释方法之间输出的因果图的差异。一方面,这促进了因果学习领域百花齐放的局面,一方面,又将人们固有的“拿到数据,放下汲桶,真相俯拾可得”的白日梦推向覆灭。